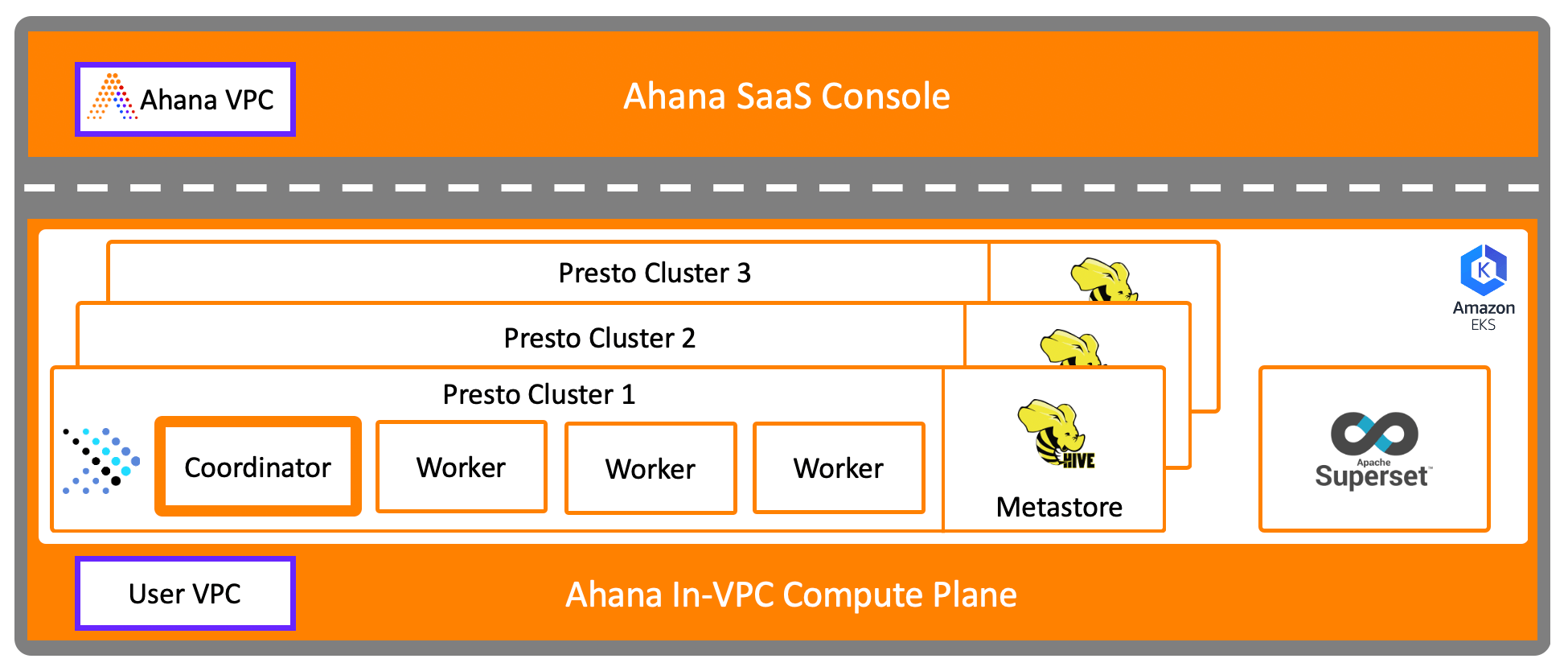
Presto Cluster Overview
Overview
For each Presto cluster created, the following resources are provisioned:
An Ahana-managed Hive Metastore - This is pre-attached to the cluster as a catalog named
ahana_hive. The Hive Metastore is provisioned as a container in an EC2 instance type of your choice. The Hive Metastore is backed by PostgreSQL, which also provisioned by Ahana as a container running on the same instance.A Presto Coordinator - The coordinator is provisioned using an EC2 instance type of your choice.
Presto Workers - The number of workers and the instance type is selected during cluster creation. The number of workers can be modified after the cluster has been created.
note
An instance of Apache Superset was provisioned during the Ahana Compute Plane creation. The Superset instance is at the Ahana Compute Plane level, and can connect to all Presto clusters in this Ahana Compute Plane. See Apache Superset Information.
Manage a Cluster
To view the details of a cluster:
In the Ahana SaaS Console, select Clusters, then select Manage for the cluster.
Information
Select Information to view basic information about the Presto cluster.
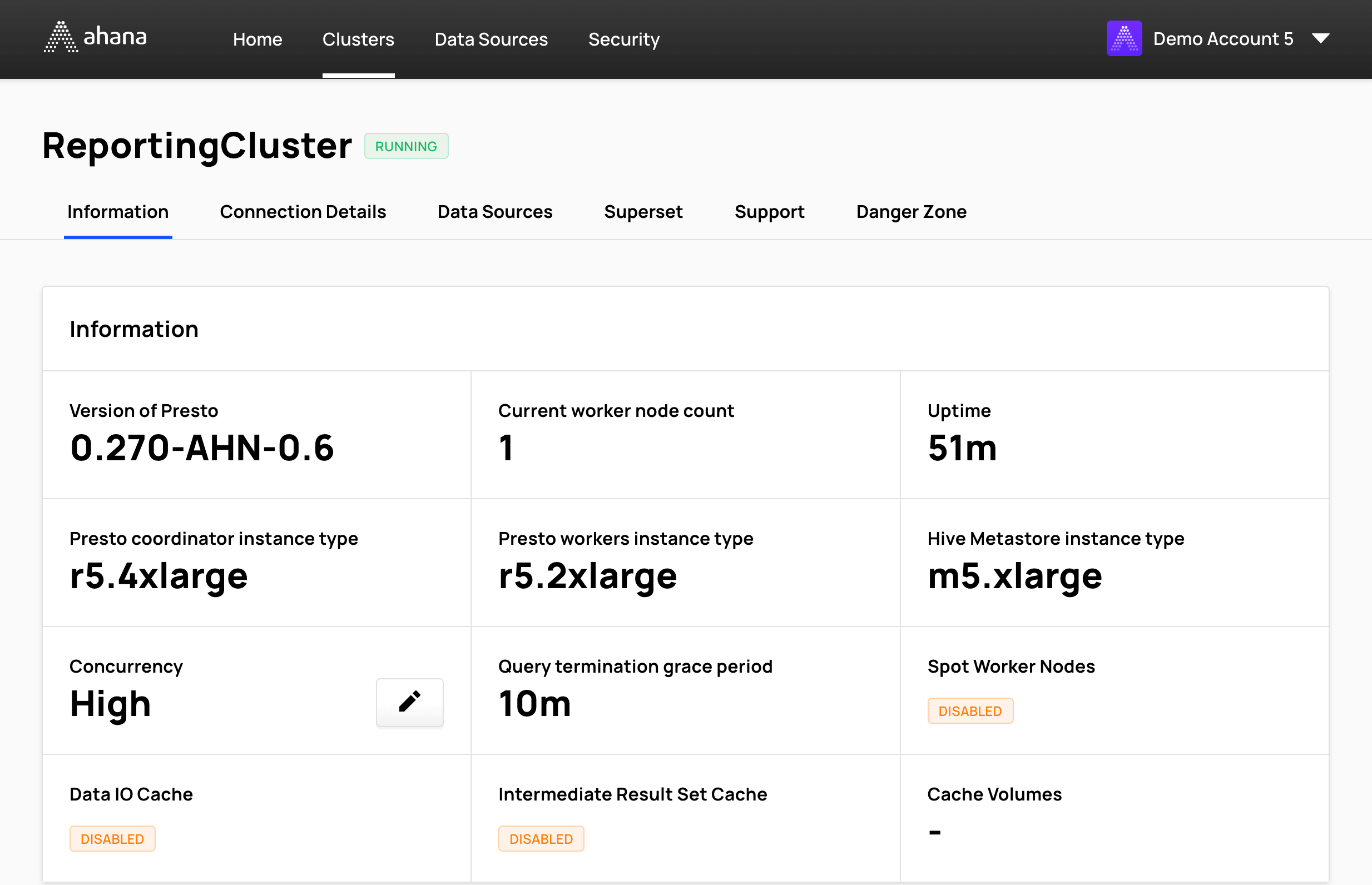
- Version of Presto - Ahana Cloud is based on PrestoDB. This field shows the version of PrestoDB that the cluster is running on.
- Current worker node count or Number of worker nodes - The current number of Presto worker nodes. The number of worker nodes can be changed after the cluster is created. See Resize a Presto cluster.
- Uptime - The duration of time from when the cluster became active last.
- Cluster instance types - The EC2 instance type for each of the cluster resources:
- Presto coordinator instance type
- Presto workers instance type
- Hive Metastore instance type - Optional. If no Hive Metastore is configured for the Presto cluster, the cell is empty. See Configure the Hive Metastore for more information.
- Concurrency - The current workload profile for the cluster. To change the workload profile of an existing cluster see Change the Workload Profile.
- Query termination grace period - The query termination grace period for the cluster.
- Data IO Cache (optional) - IO cache backed by a local AWS EBS SSD drive per worker node.
- Intermediate Result Set Cache (optional) - Intermediate result set cache backed by a local AWS EBS SSD drive per worker node.
- Cache Volumes - If either Data IO Cache or Intermediate Result Set Cache is enabled, this cell displays either View EBS Volumes or Instance Storage. Selecting View EBS Volumes opens the AWS EC2 Console to display provisoned EBS volumes.
note
If the selected Worker Node Instance Type is a type d instance - for example, ‘c5d.xlarge’ - then both Data IO Cache and Intermediate Result Set Cache are automatically enabled using the instance storage instead of AWS EBS SSD volumes.
Cluster Scaling
Depending on the cluster's configuration, Cluster Scaling displays:

- Default worker node count
- Time window before scaling to a single node
or
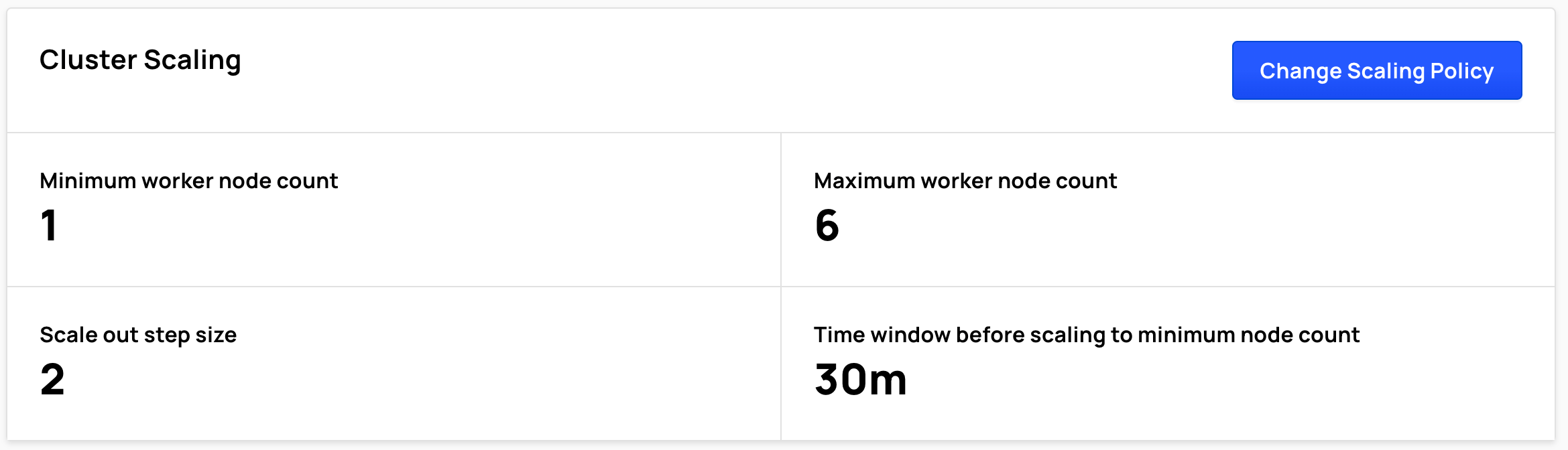
- Minimum worker node count
- Maximum worker node count
- Scale out step size
- Time window before scaling to minimum node count
To change cluster scaling, select Change Scaling Policy.
See:
Connection Details
Select Connection Details to view information about the cluster endpoints.
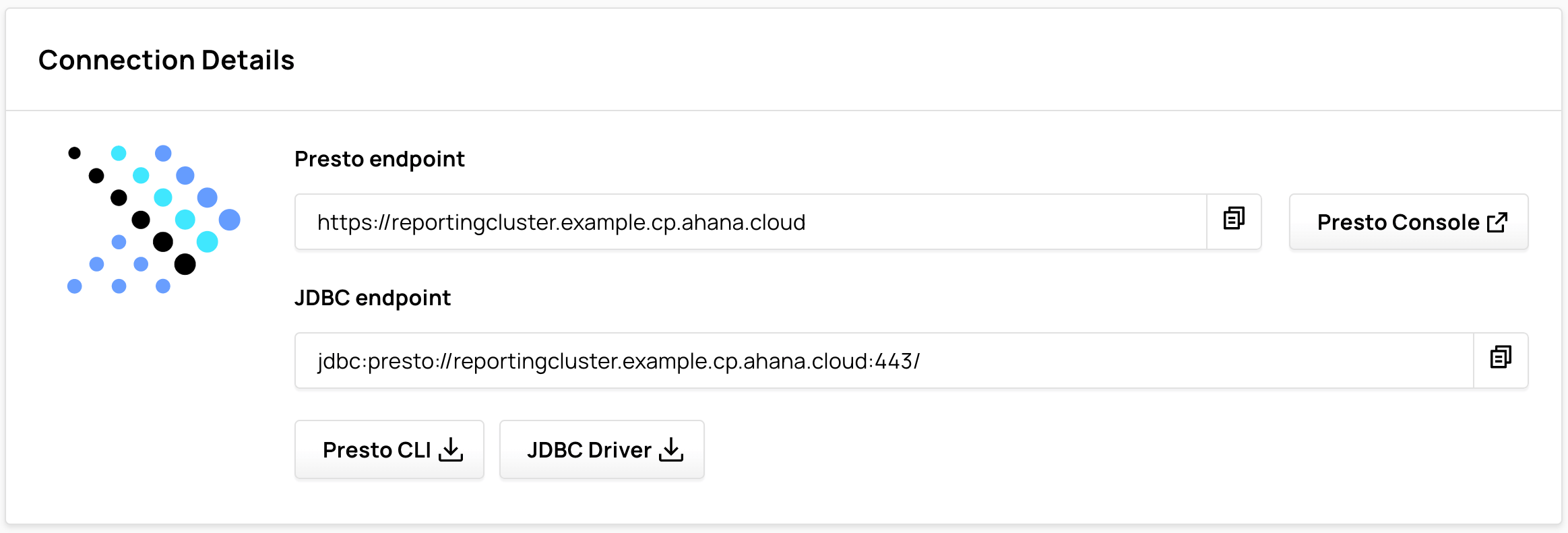
Use the Presto endpoint to connect the cluster to tools such as the Presto CLI.
./presto --server https://reportingcluster.my-domain.cp.ahana.cloud --user Admin --password
Select Presto Console to open the Presto Console for the cluster.
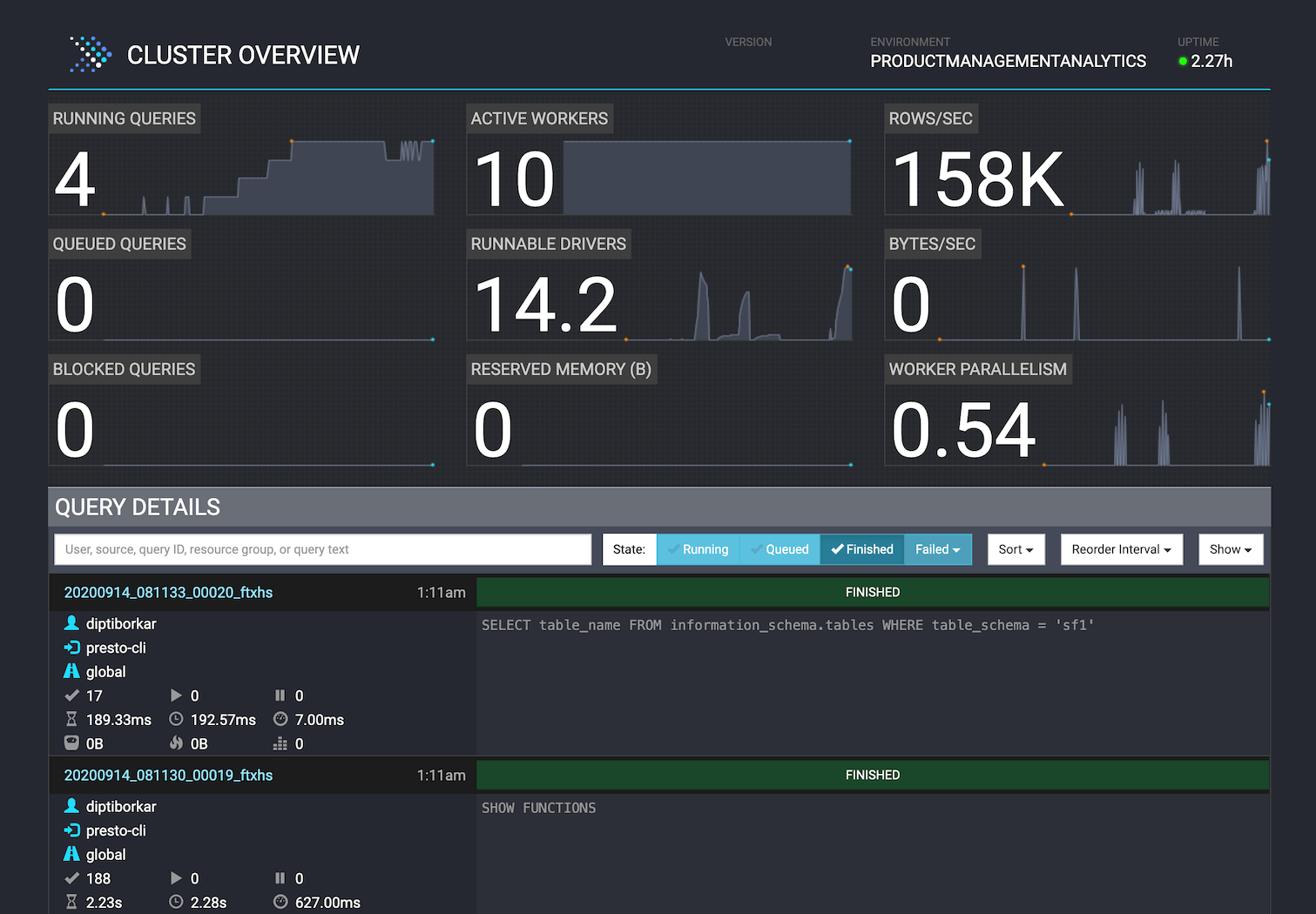
Use the JDBC endpoint to connect the cluster to tools such as Tableau, Looker, and other reporting and dashboarding tools.
Select Presto CLI or JDBC Driver to download the Presto CLI or the JDBC driver.
For more information about how the endpoints are defined, see Endpoints.
tip
Select the ![]() icon to copy connection information and other details about the cluster.
icon to copy connection information and other details about the cluster.
Identity Provider
If the Presto cluster was created after an identity provider has been configured, the Identity Provider Configuration is displayed here. See Add an Identity Provider.
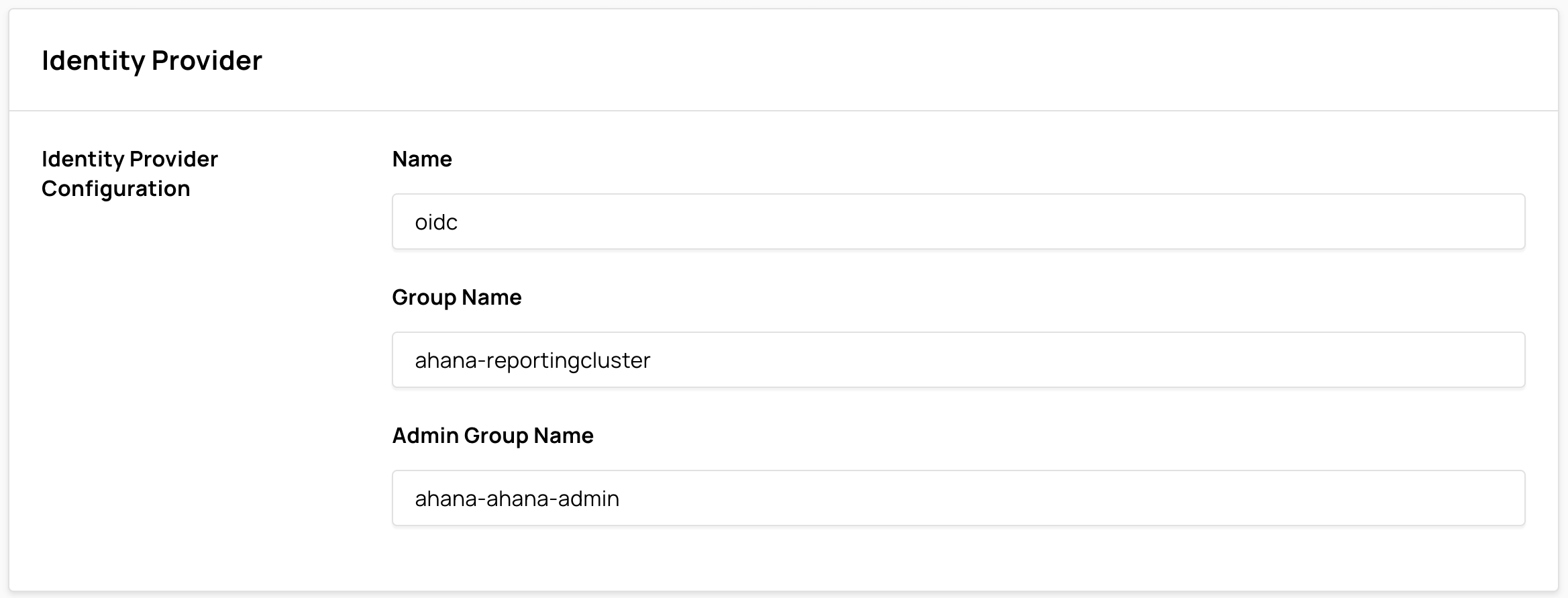
note
To enable identity providers in Ahana, contact Ahana Support.
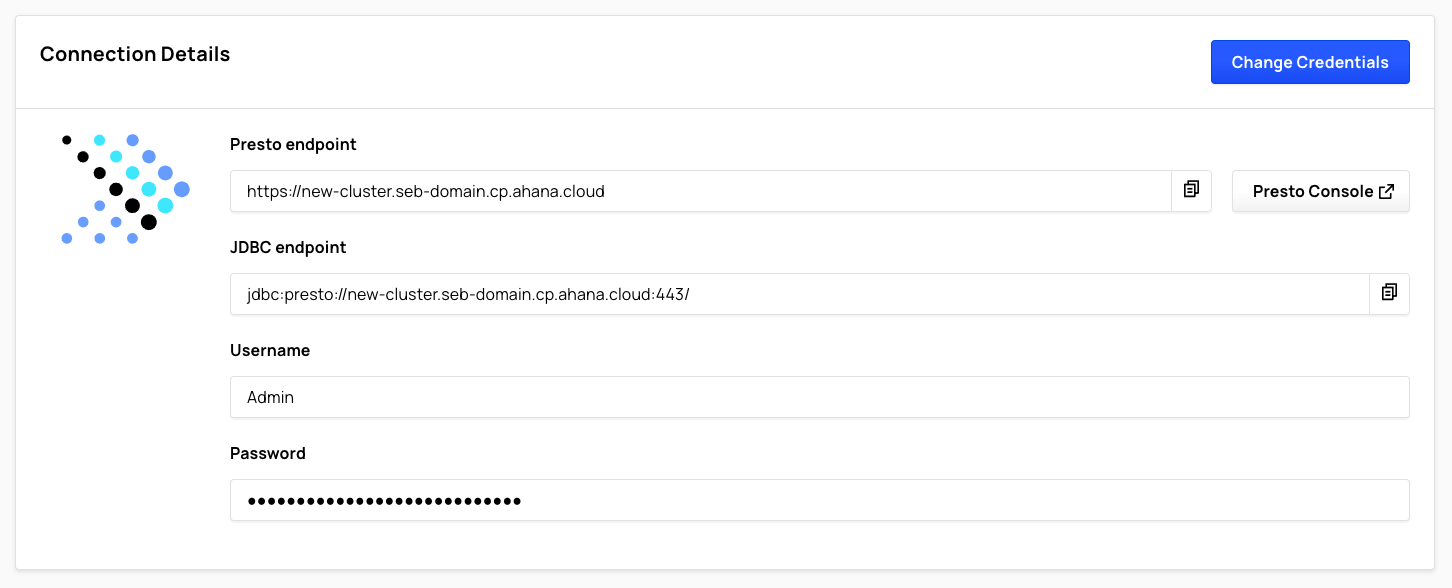
Presto Users
Presto clusters created with Ahana Compute Plane versions below 3.0 only support a single Presto user per cluster. For these clusters, Connection Details displays Username and Password fields.
Select Change Credentials to change the single Presto user's credentials.
info
If you are on an Ahana Compute Plane version below 3.0 and would like to be upgraded, reach out to your Ahana representative or Contact Ahana Support. After it is upgraded, any existing single user Presto clusters can be migrated to use multiple Presto users.
Presto clusters created with Ahana Compute Plane versions of 3.0 or higher display Presto user information in Presto Users. All Presto users in the cluster are listed in alphabetical order.
To view the details of a Presto user, select View for that user.
To add or remove Presto users from the cluster, select Manage Presto Users. See Manage Presto Users.

Ahana-managed Catalog and Storage
Ahana-managed Catalog and Storage displays the Hive Metastore Catalog Name and the name of the Ahana-managed S3 bucket.
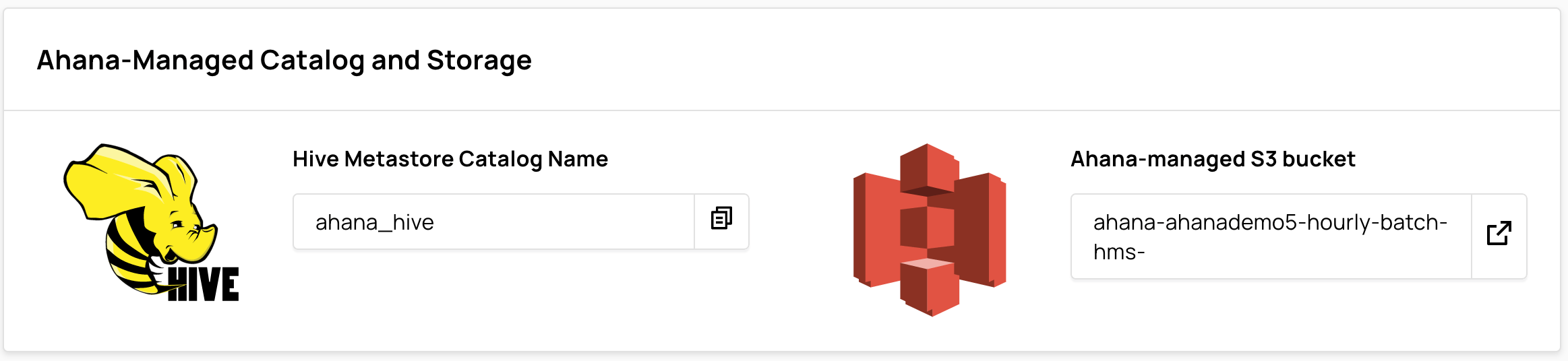
For more information, see Presto Cluster Storage.
Data Sources
Select Data Sources to view the attached data sources and catalogs of the cluster.
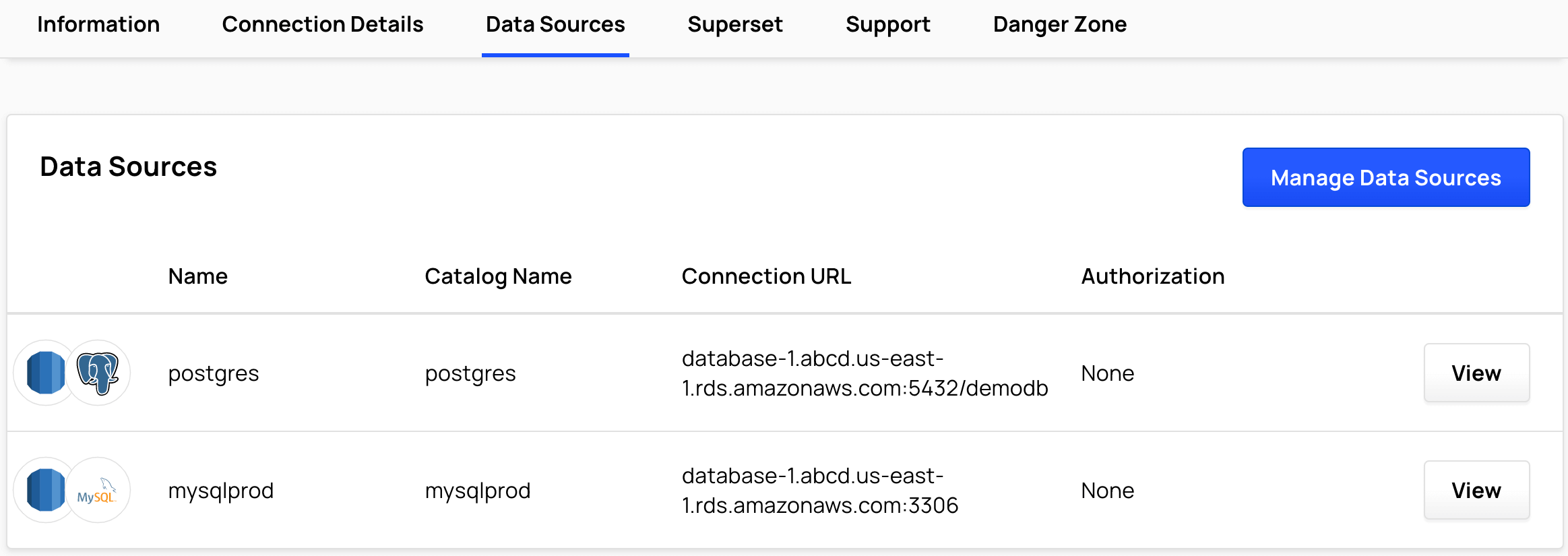
Select Manage Data Sources to change which data sources are attached to the cluster. See Data Sources Overview.
Apache Superset Information
The Ahana Compute Plane provisions an instance of Apache Superset, a popular open source dashboarding tool.
Select Superset to view Apache Superset Information.
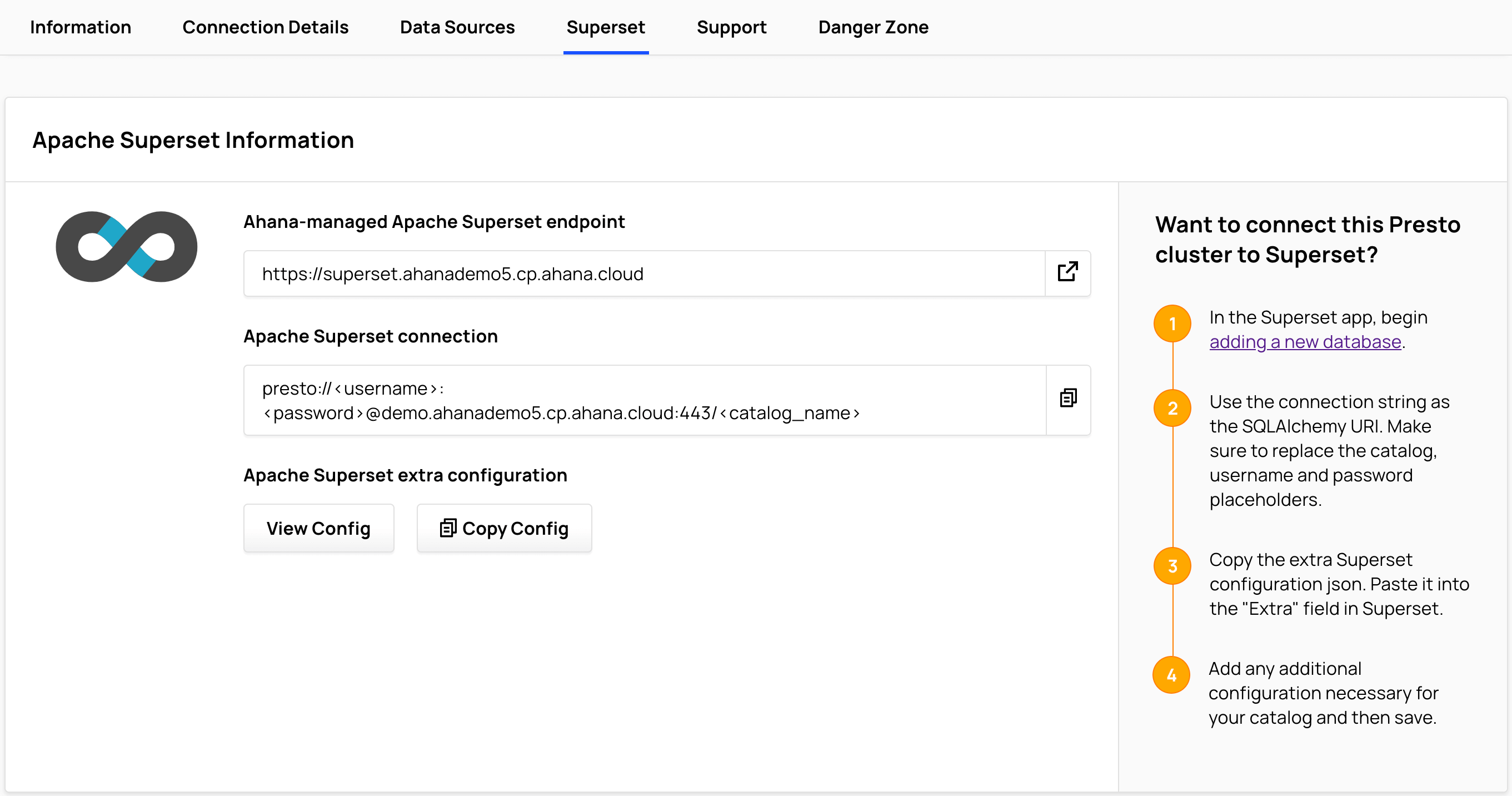
Apache Superset runs in a container on Amazon EKS on a t3.medium instance. This Superset instance is provided as an administrator sandbox to test cluster connectivity. For reporting and dashboards Ahana recommends connecting tools such as Tableau, Looker, Preset, and others to Presto using the JDBC driver.
See Query Presto Cluster with Apache Superset for more information about configuring and using Apache Superset with Ahana.
Support
Select Support.
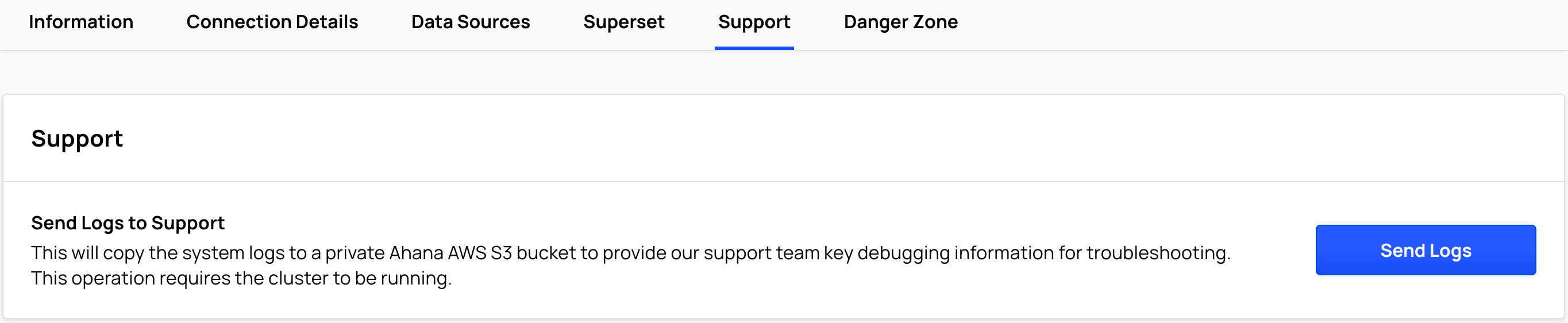
See Share Cluster Logs with Ahana Support.
Danger Zone
Select Danger Zone.
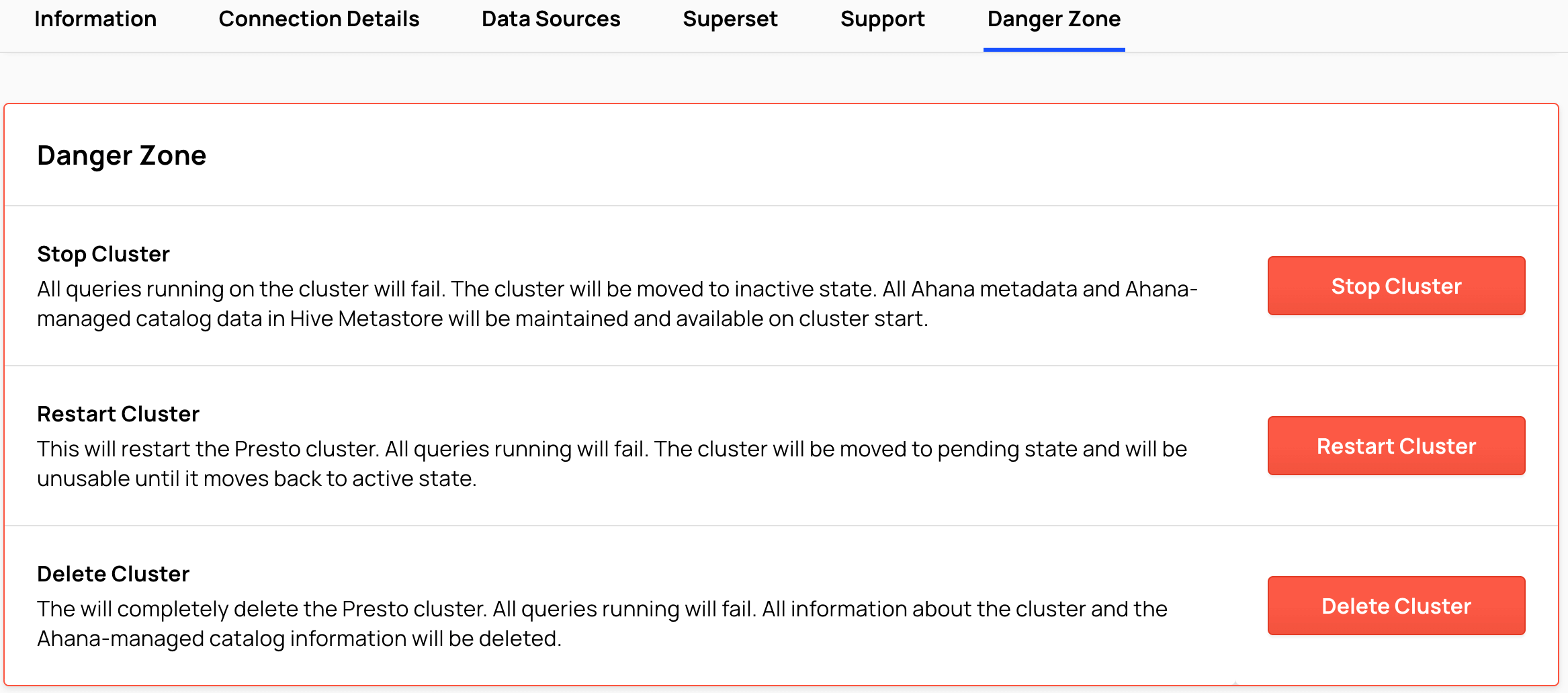
See: