What is Presto?
Presto is a distributed SQL query engine designed to query data spread over one or more different data sources - relational and non-relational databases, datalakes and other. It enables analytics on large amounts of data using ANSI SQL.
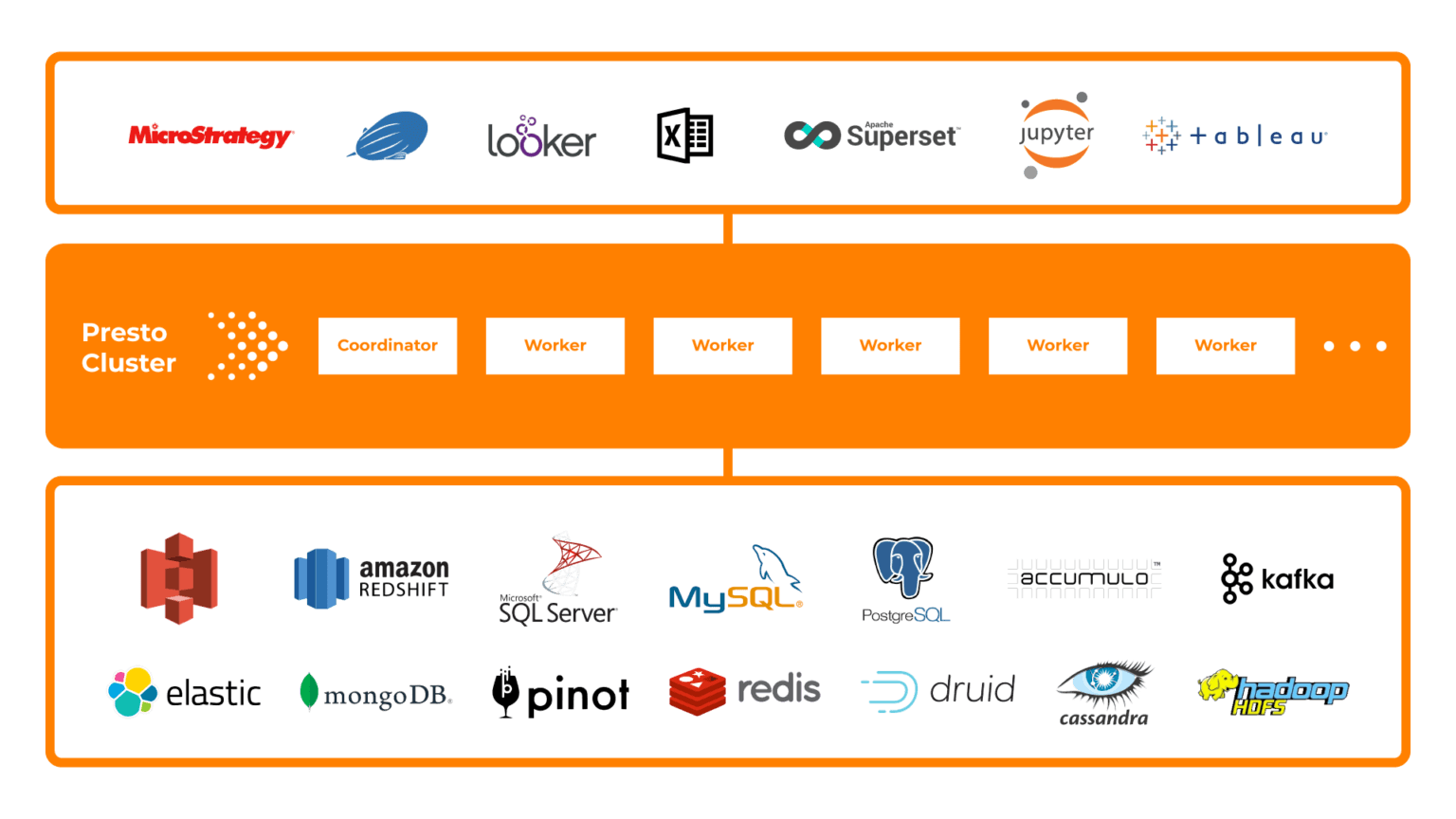
Presto Architecture
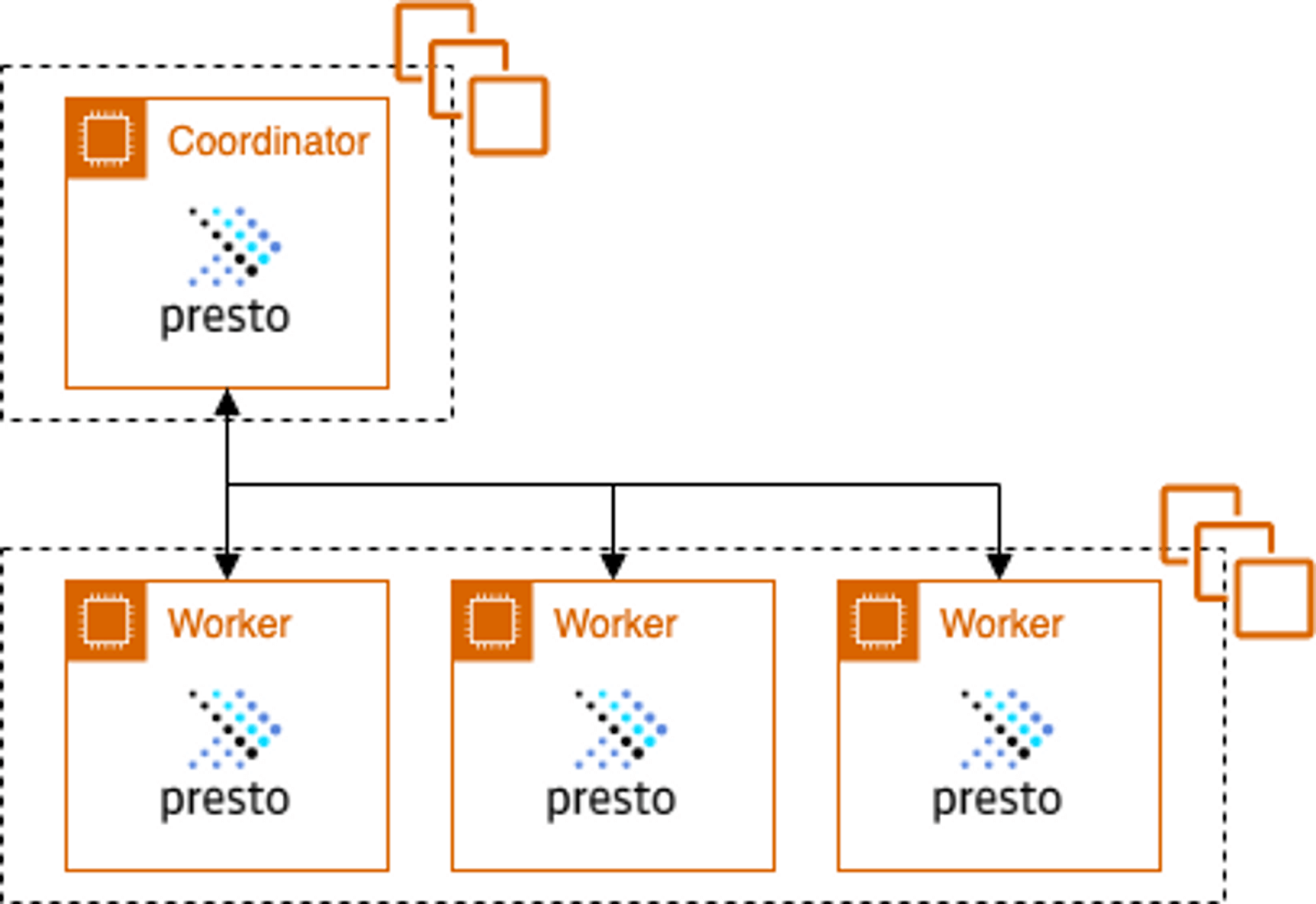
Coordinator and Worker nodes
Presto's architecture is a distributed system design that separates the activities of planning work and the actual processing of work, permitting Presto to scale with data sizes.
A Presto cluster contains a Coordinator node, and one or more - sometimes hundreds - of Worker nodes.
The Coordinator node in a Presto cluster receives an ANSI-compatible SQL statement from a client, such as the Presto CLI, Looker, or Tableau. The Coordinator node parses the statement and plans the work of converting that statement into a query, creates a query plan of tasks, then sends those tasks to Worker nodes. The Coordinator node receives task results from the Worker nodes and assembles those results into a final result which it returns to the client.
A Worker node receives, performs, and returns the results of tasks to the coordinator node. To perform their assigned tasks, worker nodes fetch data from data sources using the appropriate connectors for those data sources.
To create a Presto cluster in Ahana, see Create a Presto Cluster.
Data Source Connectors
A data source connector is a model of a three-level hierarchy — catalog, schema, and table — that presents a data source's data as tables whether or not the data source is natively relational or not. Presto uses data source connectors to manage the details of converting the native data source format to a uniform table format that you can query with SQL.
For more information on data source connectors in Ahana, see Data Sources Overview.
The Presto Foundation
The Presto Foundation oversees the development of the Presto open source project, and is part of the Linux Foundation to promote open governance and community stewardship. For more information, see Join the Presto Foundation.